使用特定领域的文档构建知识图谱
译者|Arno
来源|github
在任何业务中,word文档都是很常见的,它们以原始文本、表格和图像的形式包含信息,所有这些都包含重要的事实。此代码模式^1中使用的数据来自维基百科的两篇文章。第一个摘自肿瘤学家Suresh H. Advani的维基百科页面,第二个摘自关于肿瘤学的维基百科页面。这些文件被压缩为archive.zip文件^2。
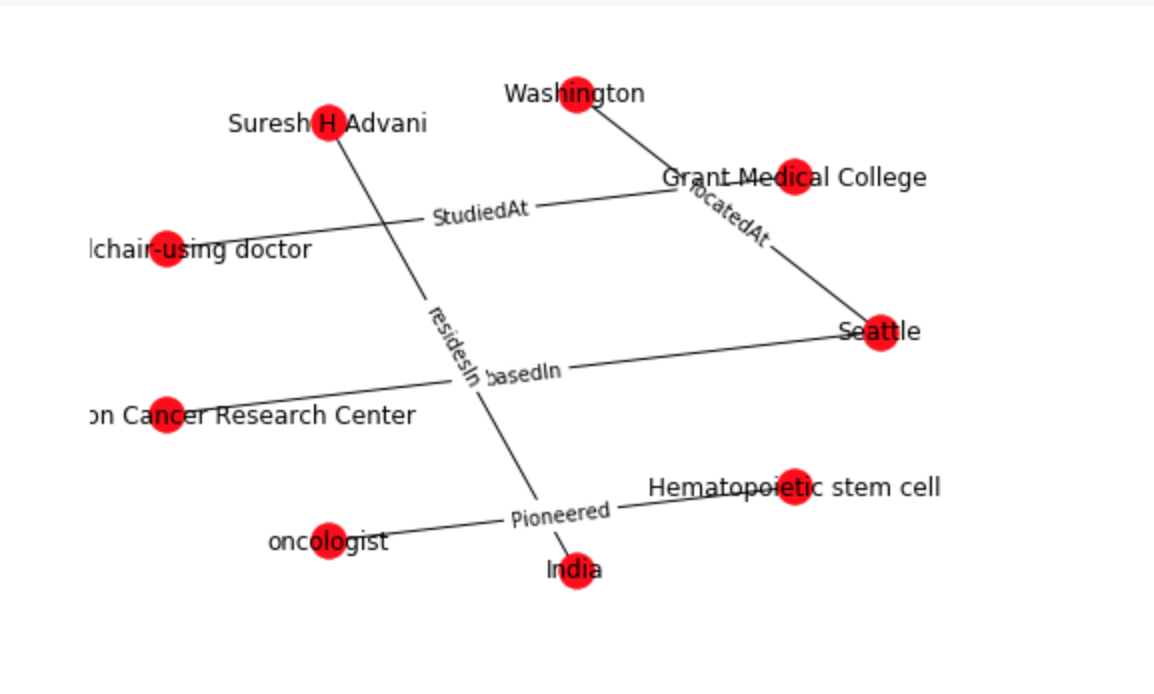
在下面的图中,有一个关于肿瘤学家Suresh H. Advani的文本信息出现在word文档中,还有一个表格包括他曾获多个机构颁发的奖项。
 在这个代码模式中,我们解决了从word文档中的文本和表格中提取知识的问题。然后从提取的知识中构建知识图谱,使知识具有可查询性。
在这个代码模式中,我们解决了从word文档中的文本和表格中提取知识的问题。然后从提取的知识中构建知识图谱,使知识具有可查询性。
而从word文档中提取知识过程中的遇到一些挑战主要为以下两个方面: 1. 自然语言处理(NLP)工具无法访问word文档中的文本。word文档需要转换为纯文本文件。 2. 业务和领域专家能够了解文档中出现的关键字和实体,但是训练NLP工具来提取领域特定的关键字和实体是一项很大的工作。此外,在许多场景中,找到足够数量的文档来训练NLP工具来处理文本是不切实际的。
在此模式中我们采用以下方法克服遇到的这些挑战: - 使用基于python的mammoth库将.docx文件转化为html文件(半结构化格式) - Watson Natural Language Understanding(Watson NLU)用于提取常见的实体。 - 使用基于规则的方法来扩展Watson NLU的输出(这种方法的解释参见代码模式Extend Watson text Classification ^3)。基于规则的方法不需要训练文档或训练工作。算法将配置文件作为输入,而此文件需要由领域专家配置。 - 使用Watson NLU提取实体之间的关系。 - 使用基于规则的方法来扩展Watson NLU的输出(这种方法的解释参见代码模式Watson Document Correlation^4)。基于规则的方法不需要训练文档或训练工作。算法将配置文件作为输入,而此文件需要由领域专家配置。
两全其美的方法--同时使用基于训练和规则的方法从文档中提取知识。
在这个模式中,我们将演示: - 从包含自由浮动的文本和表格文本的文档中提取信息。 - 清理数据^3模式以从文档中提取实体 - 使用Watson Document Correlation^4模式提取实体之间的关系 - 从提取的知识中建立一个知识图谱。
是什么让这个代码模式具有价值: - 处理docx文件中的表格和自由浮动文本的能力。 - 以及将Watson NLU的实时分析结果与主题专家或领域专家定义的规则的结果相结合的策略。
此代码模式旨在帮助开发人员、数据科学家为非结构化数据提供结构。这可以显著地帮助他们进行分析,并将数据用于进一步处理以获得更好的见解。
流程

- 需要分析和关联的docx文件 (html表格和自由浮动文本) 中的非结构化文本数据使用python代码从文档中提取。
- 使用代码模式 Extend Watson text classification^3,文本使用Watson NLU进行分类,并进行标记。
- 使用代码模式Correlate documents^5,将文本与其他文本关联
- 使用python代码过滤结果。
- 构建了知识图谱。
此外,你可以通过视频^6观看知识图谱的构建过程.
所包含的组件
- IBM Watson Studio: 使用RStudio、Jupyter和Python在一个配置好的协作环境中分析数据,其中包括IBM的value-adds,比如managed Spark。
- -Watson Natural Language Understanding: 一种IBM云服务,可以使用自然语言理解分析文本,从概念、实体、关键字、类别、情感、关系、语义角色等内容中提取元数据。
- Jupyter Notebooks: 一个开源的web应用程序,允许你创建和共享包含实时代码、方程式、可视化和解释性文本的文档。
构建步骤
按照以下步骤设置和运行此代码模式,下面将详细描述这些步骤。 - 创建IBM云服务 - 使用IBM Watson Studio中的Jupyter Notebooks运行代码 - 分析结果
1.创建IBM云服务
创建IBM云服务^7并将其命名为wdc-NLU-service。
2. 使用IBM Watson Studio中的Jupyter Notebooks运行代码
- 创建一个新的Watson Studio项目
- 创建notebook
- 运行notebook
- 上传数据
- 保存和分享
2.1 创建一个新的Watson Studio项目
- 登录到IBM的 Watson Studio,登录后,你将看到仪表板。
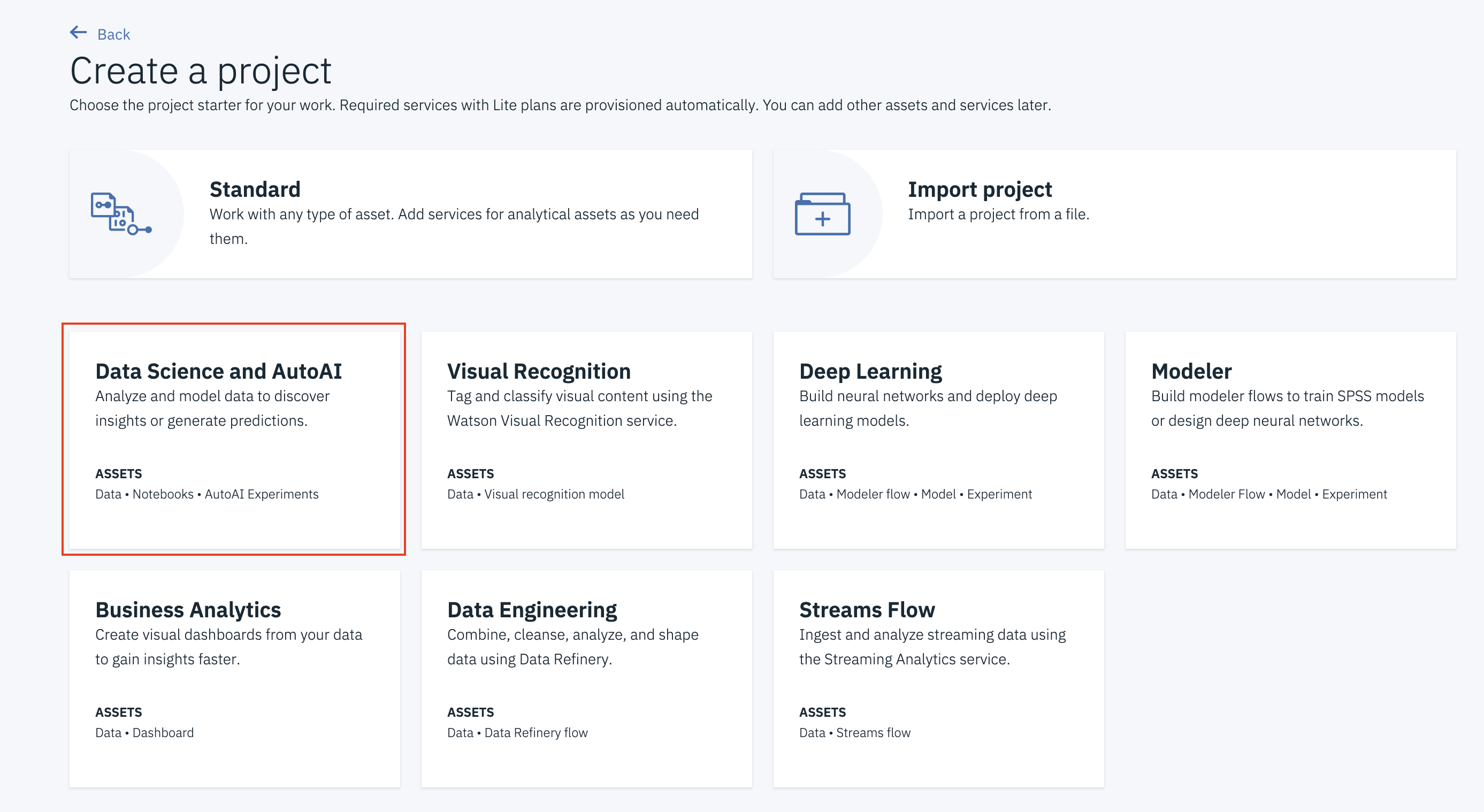
- 通过点击
New project并选择Data Science创建一个新项目。
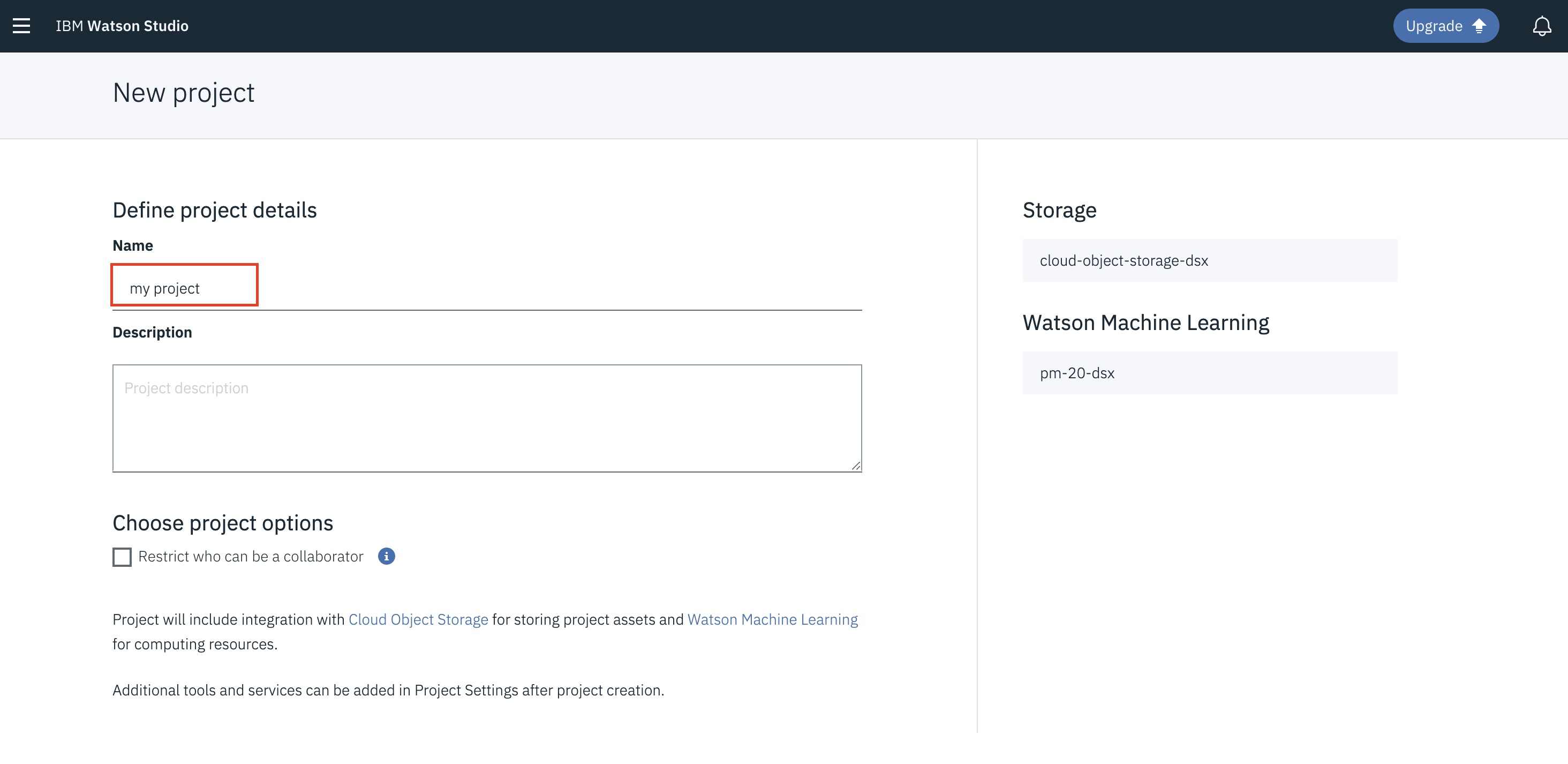
- 为项目起一个名称并点击
Create。 - 注意: 通过在Watson Studio中创建一个项目,一个免费的
Object Storage服务和Watson Machine Learning服务将在你的IBM Cloud帐户中创建。选择免费存储类型以避免收费。
2.2创建notebook
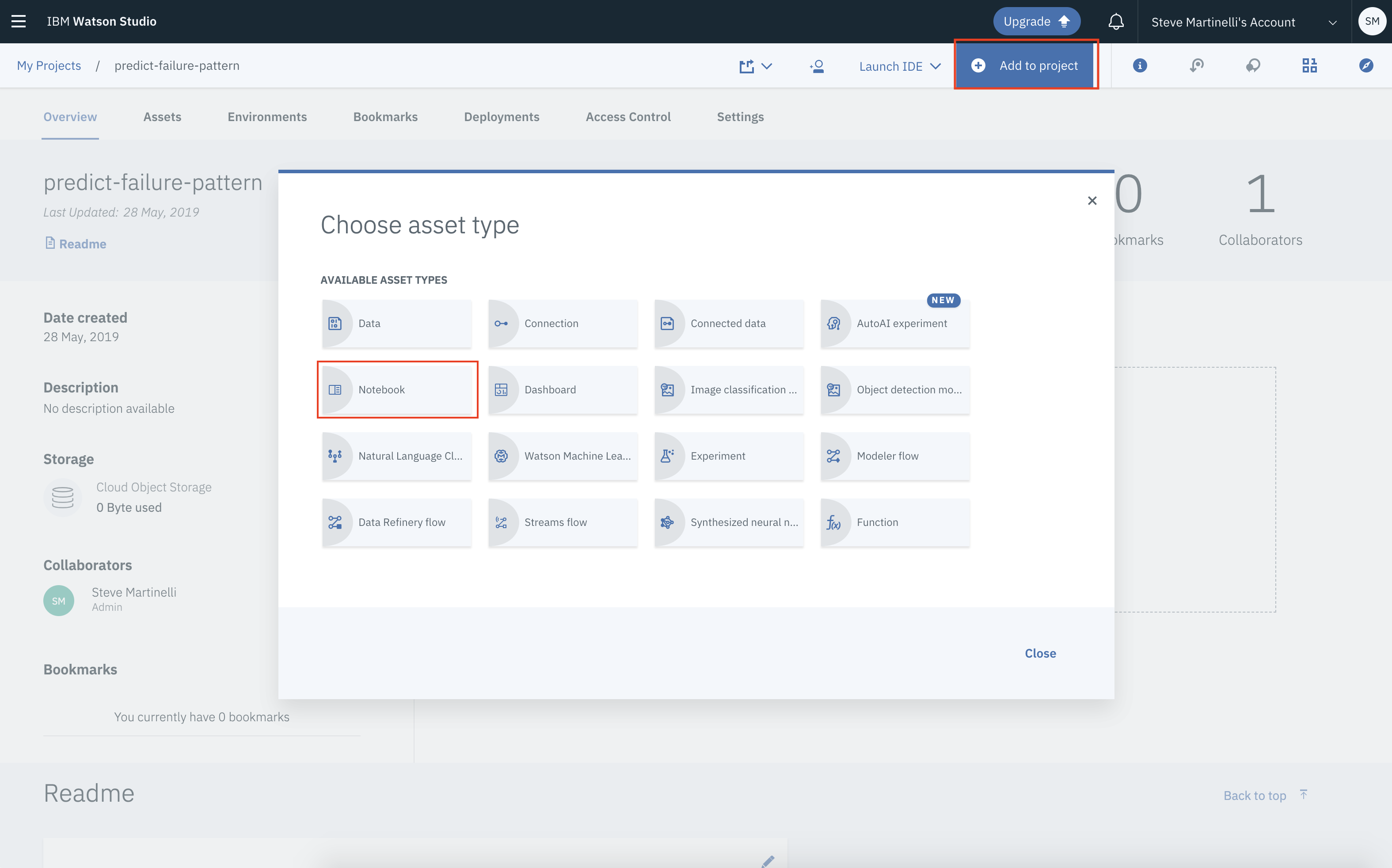
- 在新建项目
Overview面板中,点击右上角的Add to project并选择Notebook资源类型。
- 填写以下信息:
- 选择
From URL选项卡。(步骤1) - 输入notebook的
名称和可选项描述。(步骤2) - 在
Notebook URL下提供以下URL: https://raw.githubusercontent.com/IBM/build-knowledge-base-with-domain-specific-documents/master/notebooks/knowledge_graph.ipynb。(步骤3) - 对于
Runtime运行环境,选择Python 3.5。(步骤4)
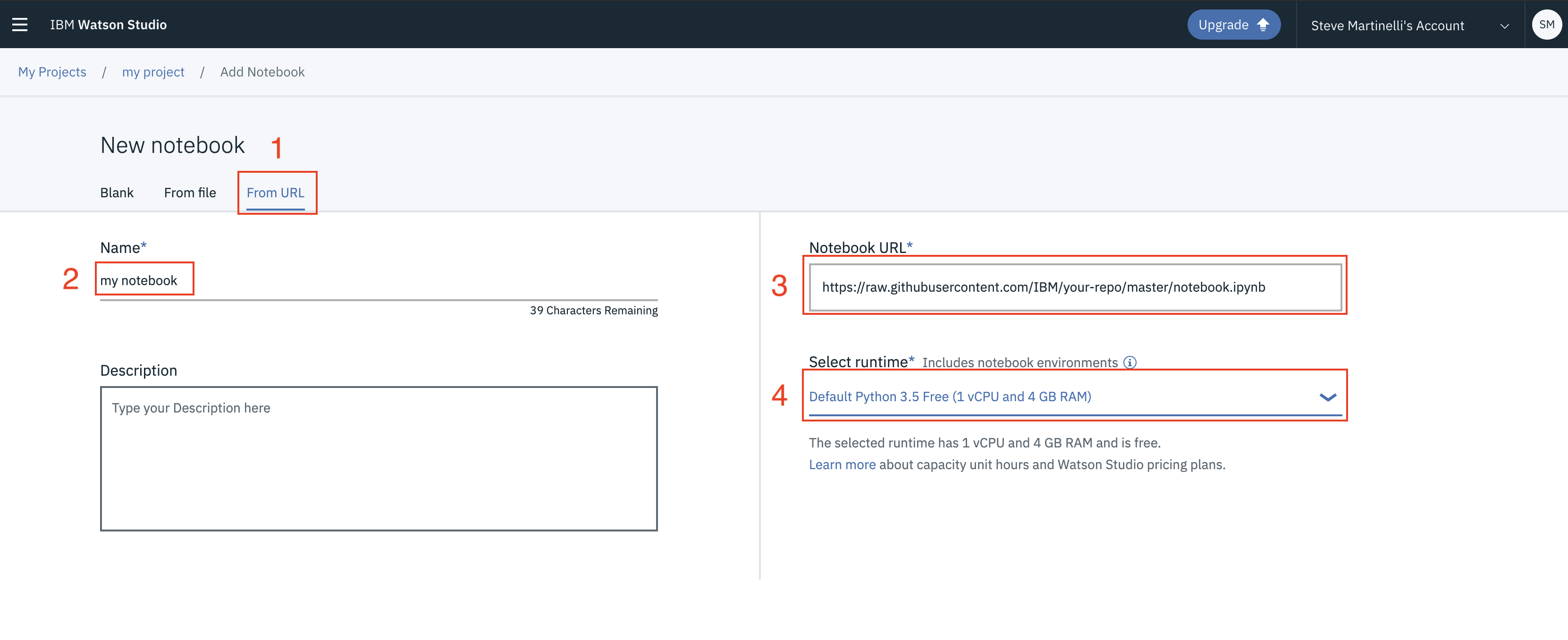
- 点击
Create按钮。 - 提示: 一旦成功导入,notebook应该出现在
Assets选项卡的Notebook部分。
2.3运行notebook
- 选择下拉菜单
Cell > Run All运行notebook,或者使用play按钮自顶向下一次运行单元格。 - 当单元格运行时,观察输出结果或错误。一个正在运行的单元格将有一个类似于In[*]的标签。一个完成的单元格将有一个运行序列号,而不是星号。
2.4上传数据
将数据和配置上传到notebook上:
- notebook使用data^2中的数据,将数据上传到我们的项目中
- 在新项目的Overview面板中,单击右上角的Add to project并选择Data资源类型。

- 屏幕右侧出现的面板将指导你如何上传数据,按照下图中编号的步骤操作。
- 确保你在
Load选项卡上。(步骤1) - 单击
browse选项。在你的机器上定位到archive.zip、config_relations.txt和config_classification.txt文件的位置,并将它们上传。(没有标记步骤) - 上传后,转到
Files选项卡。(步骤2) - 确保文件出现图中的位置。(步骤3)
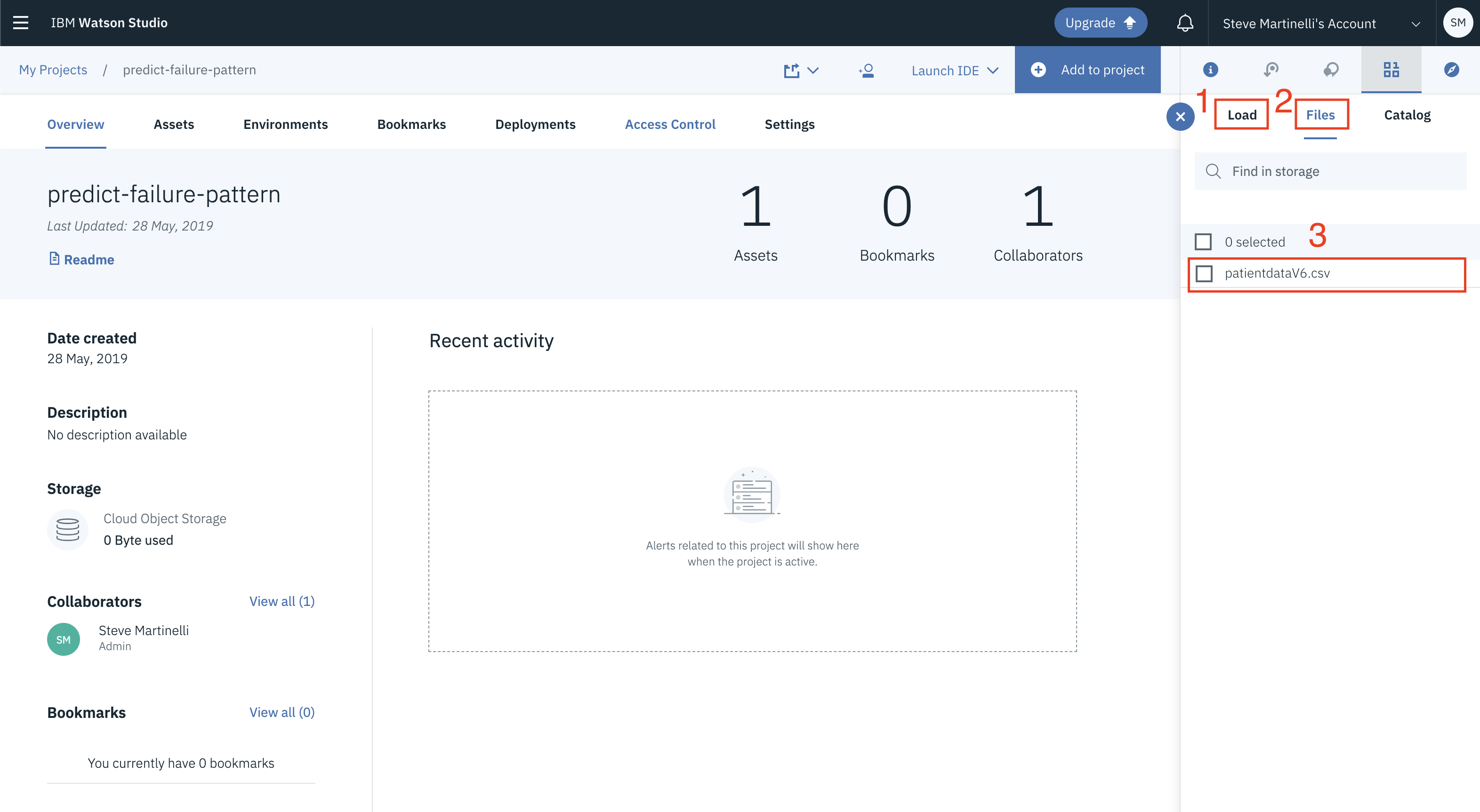
注意:可以使用你自己的数据和配置文件。如果使用自己的配置文件,请确保符合
config_classification.txt文件中给出的JSON结构。
3.分析结果
当我们浏览notebook时,我们首先要做的是:
- 配置文件(config_classification.txt和config_relations.txt)已经被加载进来
- 使用python包mammoth提取非结构化的信息,Mammoth将.docx文件转换为.html,并分析表格中的文本和自由浮动文本
- 使用配置文件分析和扩展Watson Natural Language Understanding的结果。
- 实体使用config_classification.txt文件进行扩展,关系使用config_relationships.txt文件进行扩展。
- 然后对结果进行过滤和格式化,以获取相关关系并丢弃不相关的关系。
- 将过滤后的关系发送到notebook中的绘制图形函数,构建知识图谱。