目录:
- 循环神经网络的应用
-
- 文本分类
- 序列标注
- 机器翻译
- Attention-based model
- RNN系列总结
- 循环神经网络的应用
根据应用场景和需求的不同,我们大致可以将循环神经网络的任务分为两类:一类是序列到类别的模式,另一类是序列到序列的模式。其中,序列到序列的问题又可以进一步的划分为:“同步的序列到序列的模式”和“异步的序列到序列的模式”。接下来我们会通过三个案例来进一步的了解这三种模式。
1.文本分类
文本分类目前是自然语言处理(Natural Language Processing,NLP)领域中最常见的问题之一,例如做垃圾邮件检测、用户评论的情感极性分析等。序列到类别的模式适用于文本分类问题,在文本分类问题中,我们输入到循环神经网络中的是一段文本,长度为n,神经网络的输出只有一个类别,长度为1。
假设我们要实现一个外卖行业的用户评论的情感极性分类,如图1所示,我们输入到神经网络中的是一段用户对外卖商品的评论。
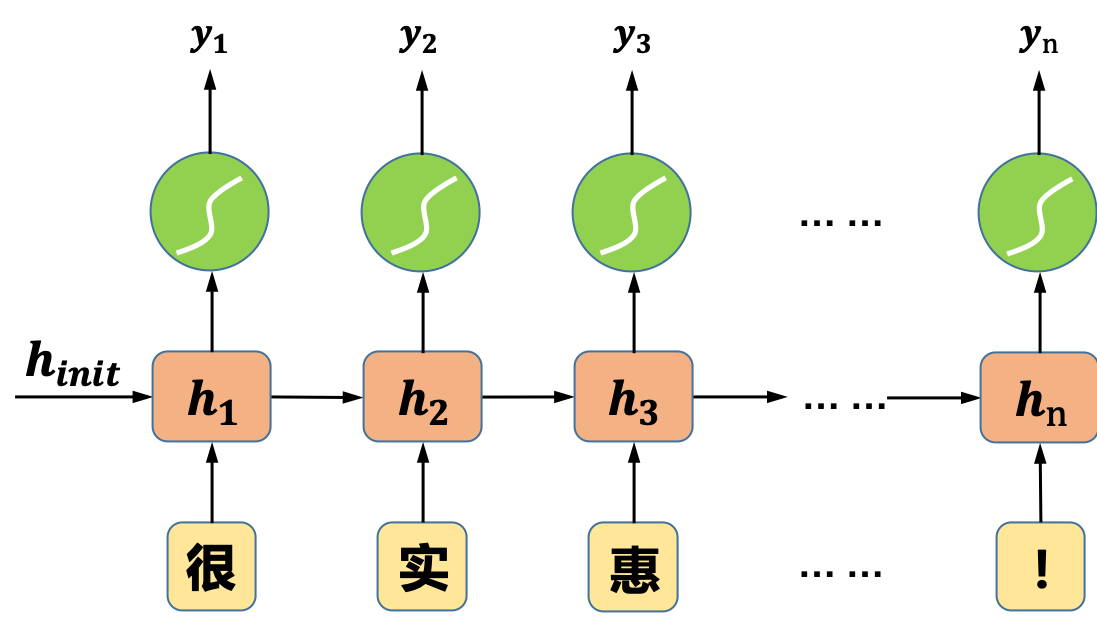
图1 实现文本分类的循环神经网络示意图
循环神经网络在每一个“时间步”都有一个输出,但对于一个简单的分类问题,我们不需要这么多的输出,一个常用且简单的处理方式是只保留最后一个“时间步”的输出,如图2所示: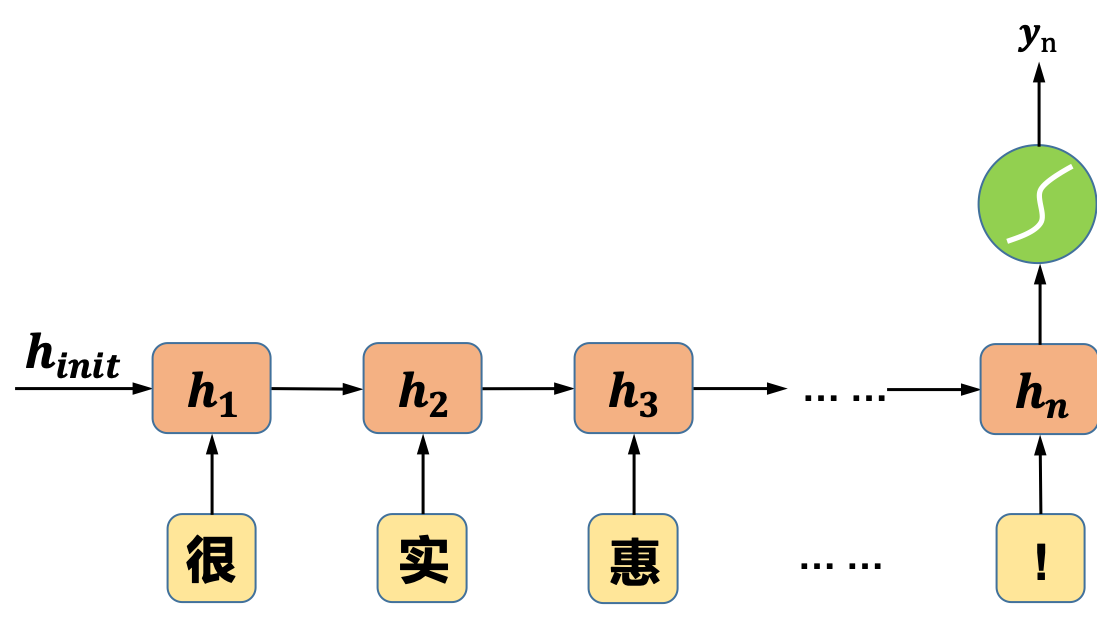
图2 “序列到类别模式”的循环神经网络示意图
2.序列标注分词是自然语言处理中最基础也是最重要的一个环节,随着深度学习的发展,不少人开始尝试将深度学习应用到这一领域,近两年里也取得了一定的成果。虽然目前在分词、词性标注等任务中普遍使用的还是CRF、HMM等传统算法,但是深度学习所取得的成果已经被越来越多的人所认可,并且不断地在自然语言处理的任务中崭露头角。
不管是使用传统的CRF算法还是使用循环神经网络来训练分词模型,我们都需要先对训练数据进行标注。以4-tag字标注法为例,假设我们有一段训练样本“北京市是中国的首都”,标注后的数据形式如下:
| 北 B |
| 京 M |
| 市 E |
| 是 S |
| 中 B |
| 国 M |
| 的 S |
| 首 B |
| 都 M |
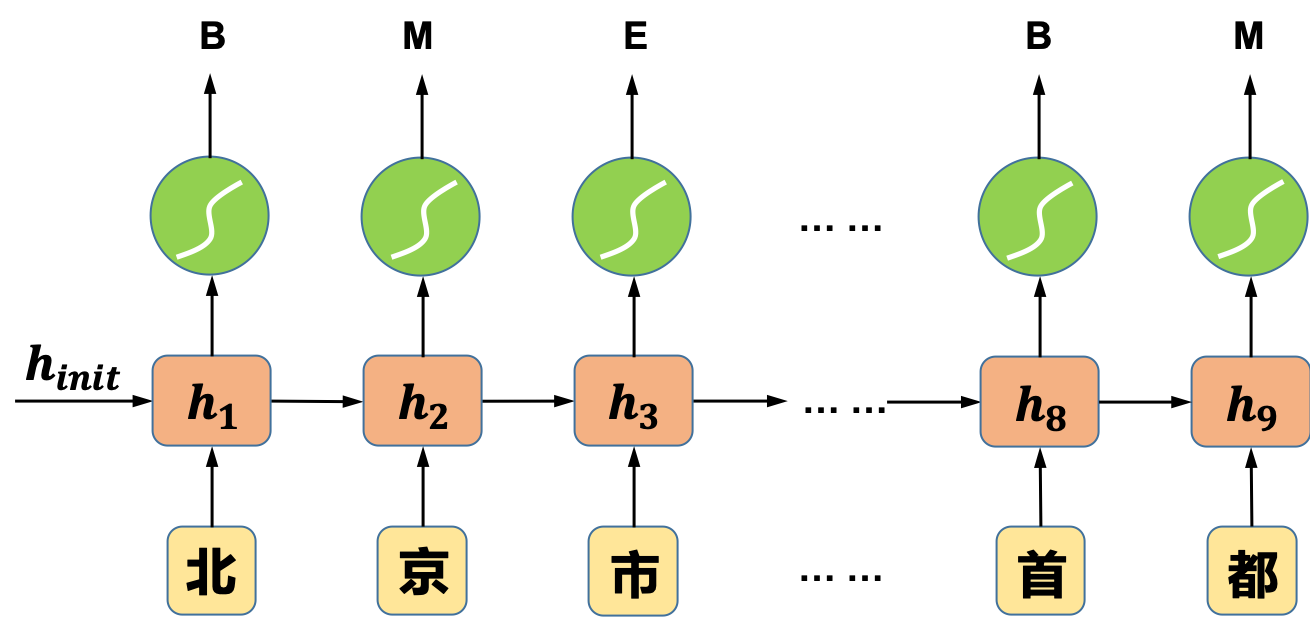
图3 “同步的序列到序列模式”的循环神经网络示意图
4.机器翻译用于机器翻译的循环神经网络是一种“异步的序列到序列模式”的网络结构,同样是序列到序列的模式,与适用于序列标注的“同步的序列到序列模式”的不同之处在于,“异步的序列到序列模式”的循环神经网络对于输入和输出的序列长度没有限制。在序列标注问题中,每一个“时间步”都有一个输入和一个对应的输出,因此输入和输出的序列长度相同,然而在机器翻译问题中,我们输入的序列长度和输出的序列长度不一定等长。
“异步的序列到序列模式”的循环神经网络就是我们常说的Sequence to Sequence model,又称为编码器-解码器(Encoder-Decoder)模型。之所以称之为编码器-解码器模型,是因为我们将网络分成了两部分:编码器部分和解码器部分。如图4所示,编码器模型对输入的序列数据进行编码,得到中间向量:
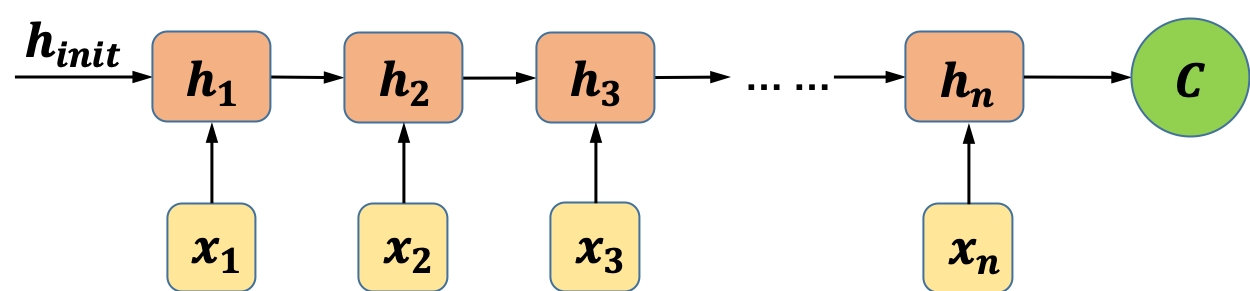
图4 编码器部分示意图
最简单的编码方式是直接把网络最后一个时刻的状态h_n赋值给C,也可以使用一个函数来做变换,函数接收的参数可以是h_n,也可以是从h_1到h_n的所有中间状态。在得到中间向量C之后,接下来要做的就是解码。一种常用的解码方式如图5(左)所示,模型在解码过程中将编码得到的向量C作为解码器的初始状态,并将每一个时间步的输出作为下一个时间步的输入,直至解码完成。“EOS”是输入和输出序列结束的标志。图5右侧所示的是另一种解码的方式,该方式将编码得到的向量C作为解码器模型每一个“时间步”的输入。更具体的Sequence to Sequence模型,可以阅读Bengio等人在2014年发表的论文[1],以及Google在2014年的一篇论文[2]。
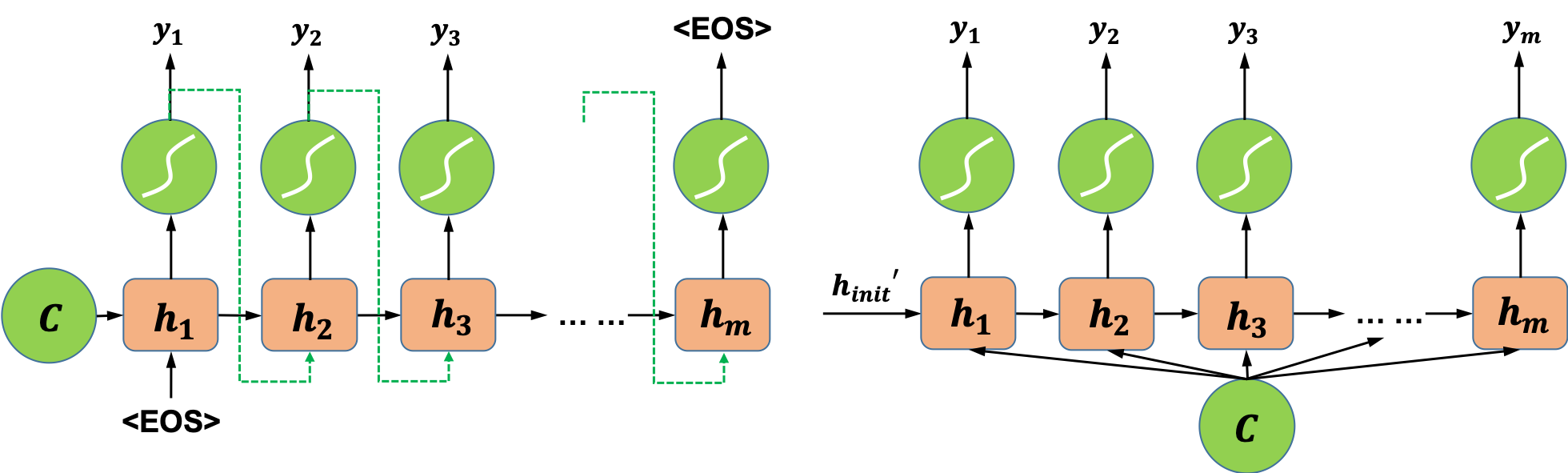
图5 两种不同的解码器模型示意图
- Attention-based model
虽然采用编码器-解码器 (Encoder-Decoder) 结构的模型在机器翻译、语音识别以及文本摘要等诸多应用中均取得了非常不错的效果,但同时也存在着不足之处。编码器将输入的序列编码成了一个固定长度的向量,再由解码器将其解码得到输出序列,这个固定长度的向量所具有的表征能力是有限的,然而解码器又受限于这个固定长度的向量。因此,当输入序列较长时,编码器很难将所有的重要信息都编码到这个定长的向量中,从而使得模型的效果大打折扣。
为了解决这一问题,我们引入了注意力机制(Attention),这种引入了Attention机制的神经网络模型又称为Attention-based model。本节我们要介绍的Soft Attention Model是一种最为常见,使用也较多的注意力模型。为了解决传统的Encoder-Decoder模型中单个定长的编码向量无法保留较长的输入序列中的所有有用信息的问题,Attention-based model引入多个编码向量,在解码器中一个输出对应一个编码向量,如图6所示。
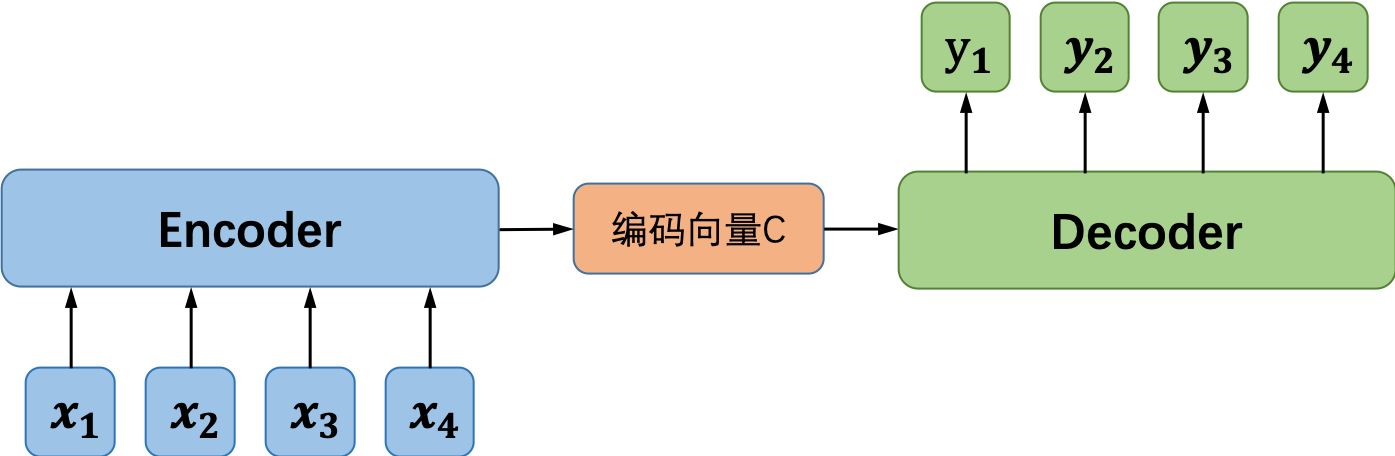
图6没有Attention机制的Encoder-Decoder模型示意图
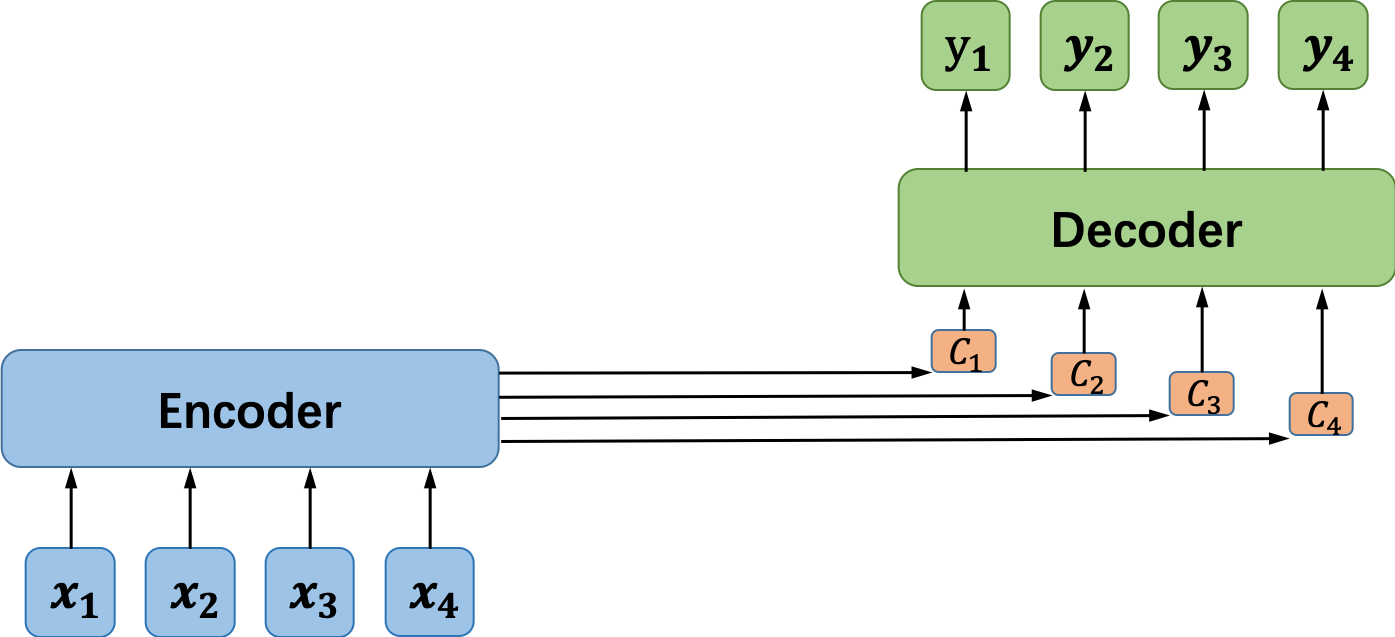
图7 Attention-based model示意图
举个简单的例子,假设解码器的输出y_1与编码器的输入x_1、x_2的关系较大,那么编码得到的向量C_1就会更多的保存x_1和x_2的信息,同理得到其它的编码向量。因此,Attention机制的核心就是编码向量C_i的计算,假设我们的编码器和解码器均使用的是循环神经网络,计算过程如图8所示。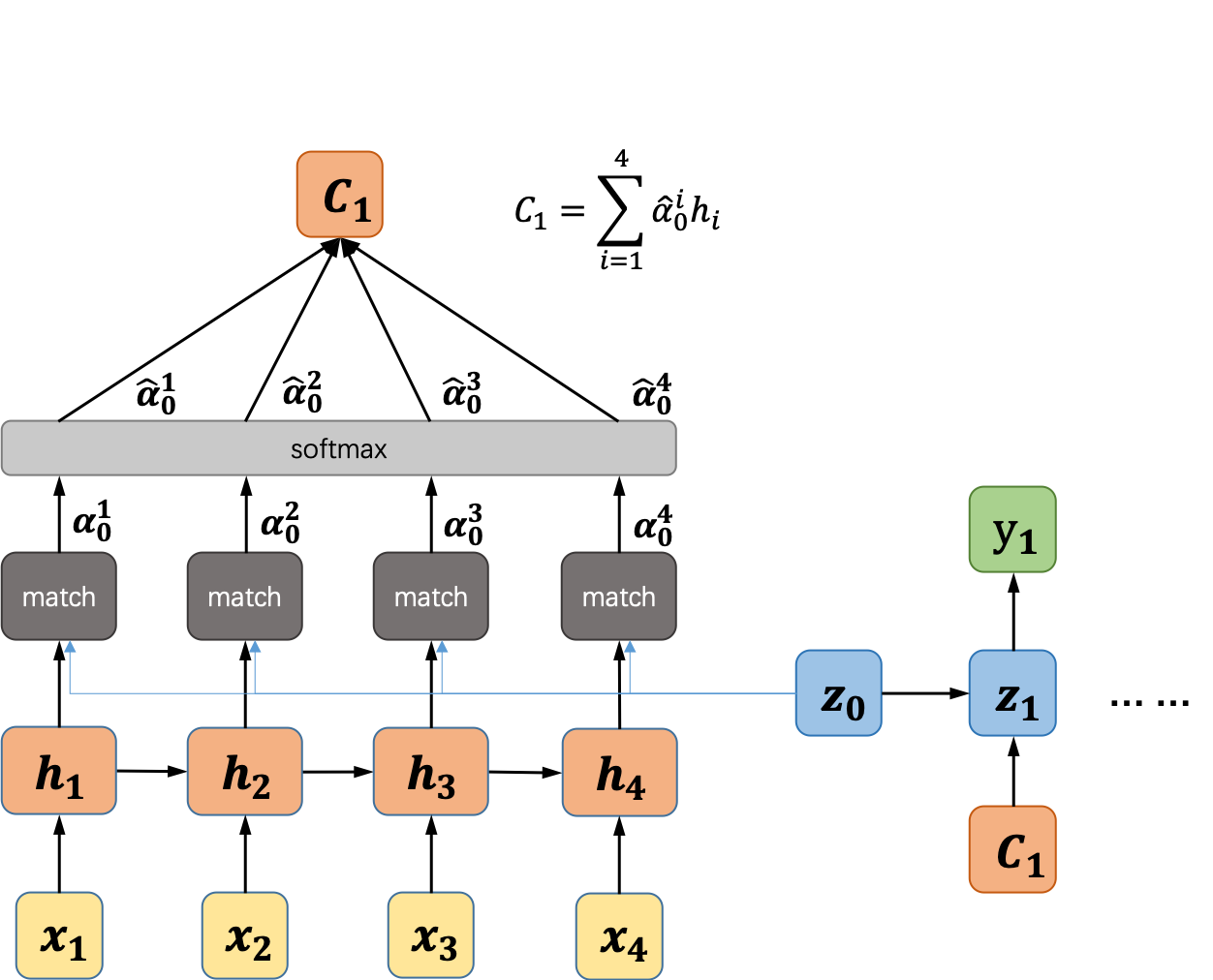
图8 Attention计算过程示意图
我们以第一个编码向量的计算为例,首先用解码器的初始状态分别和编码器中每个时间步的输出计算相似度,得到输出,再通过一个softmax运算将转换成概率值,最后由公式计算得到编码向量。接下来再利用解码器中神经网络的输出计算编码向量,以此类推,直到解码过程结束。以上就是传统的Soft Attention Model,除此之外还有一些其它形式的Attention-based model,有适用于自然语言处理领域的,也有适用于图像领域的。Google在2017年发表的一篇论文《Attention is All You Need》[3],试图摆脱CNN和RNN,想要用纯粹的Attention来实现Encoder-Decoder模型的任务,并且取得了非常不错的效果。
- RNN系列总结
在下一章里,我们将使用循环神经网络实现几个完整的项目,在学会使用TensorFlow搭建循环神经网络模型的同时,加深对循环神经网络的理解。
- 参考文献
[2] Google: Sequence to Sequence Learning with Neural Networks
[3]Google: Attention is All You Need