知识图谱与机器学习 | KG入门 -- Part2 建立知识图谱
在能够开发Data Fabric之前,我们需要构建一个知识图谱。在本文中,我将建立如何创建它的基础,在下一篇文章中,我们将讨论如何实现这一点

编译|Arno
来源|Medium
介绍
在本系列前面两篇文章中我一直在讨论Data Fabric,并给出了一些关于Data Fabric中的机器学习和深度学习的概念。并给出了我对Data Fabric的定义:
Data Fabric是支持企业所有数据的平台,它作为一个统一的框架来管理、描述、组合和访问数据。该平台由企业知识图谱构成以创建统一的数据环境。
如果你仔细看一下定义,它说Data Fabric是由企业知识图谱构建的,所以我们最好知道如何创建和管理它。
目标
建立了知识图谱理论的基础和讲解如何构建一个知识图谱
细节
- 解释与企业相关的知识图谱的概念
- 给出构建成功的企业知识图谱一些建议
- 展示知识图谱的例子
主要理论
Data Fabric中的fabric是由一个知识图谱构建的,而要创建一个知识图谱,你需要语义和本体来找到一种有用的方法来链接数据,这种方法惟一地标识数据并将数据与公共业务术语连接起来。
第一节 什么是知识图谱?

知识图谱由数据和信息组成,还包含大量不同数据之间的链接。
这里的关键是,在这个新模型下,我们不是在寻找可能的答案,而是在寻找确定的答案。我们想要的是事实——这些事实来自哪里并不那么重要。这里的数据可以代表概念、对象、事物、人,以及你头脑中的任何东西。图中填充了概念之间的关系和联系。
在这种情况下,我们可以向我们的数据湖提出这个问题:这里存在什么?
这里不同的是它可以建立一个框架来研究数据及其与其他数据的关系。在知识图谱中,表示在特定形式本体中的信息可以更容易地进行自动化信息处理,而如何最好地实现这一点是计算机科学(如数据科学)中一个活跃的研究领域。
本体语言中的所有数据建模语句(以及其他所有东西)和数据知识图谱的世界本质上都是递增的。通过修改概念,可以很容易地在事后增强或修改数据模型。
通过知识图谱,我们构建的是一种人类可读的数据表示,它惟一地标识数据,并将数据与常见的业务术语连接起来。这个“层”帮助终端用户自主、安全、自信地访问数据。
还记得这张图片吗?

我之前提过Data Fabric中的“洞察力”(insight)可以看作是对其的一个凹痕。而发现这种“洞察力”是什么的自动过程,就是机器学习。
但这种fabric是什么呢?是由知识图谱构成的对象。就像在爱因斯坦的相对论中,时空的连续体(或离散体?)构成了fabric,而在这里,当你创建一个知识图谱时,fabric就形成了。
为了构建知识图谱,你需要链接数据。链接数据的目标是发布结构化数据,使其易于使用,并与其他链接数据相结合,本体作为连接实体和理解实体之间关系的方式。
第二节 创建一个成功的企业知识图谱

不久前Sebastien Dery写了一篇关于知识图谱挑战的有趣文章。这里你可以看一看
https://medium.com/@sderymail/challenges-of-knowledge-graph-part-1-d9ffe9e35214
也可以看看cambridgesemantis.com上关于RDF的介绍以及其他资源,我在任何文章中都没有提到,但非常重要的一个概念是三元组的概念:主语、宾语和谓语(或实体-属性-值)。通常,当你研究三元组时,它们实际上是指资源描述框架(RDF)。
RDF是三种基本语义Web技术之一,另外两种是SPARQL和OWL。并且RDF是语义Web的数据模型。
注意:顺便说一下,这些概念几乎都是随着万维网语义的新定义而来的,但是我们将它用于知识图谱。
我不打算在这里详细描述这个框架,但是我将给出一个关于它们如何工作的例子。记住,我这样做是因为这是我们开始构建本体、链接数据和知识图谱的方式。
让我们看一个例子,看看这个三元组是什么,这与Sebastien提到的例子密切相关。
我们将从字符串“geoffrey hinton”开始。

现在,要开始构建一个知识图谱,首先系统要识别那个字符串实际上指的是Geoffrey Hinton这个人。然后它会识别那个人的相关实体。
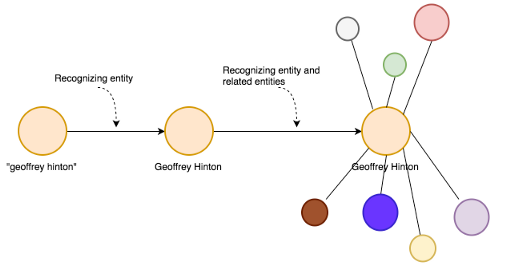
顺便说一下,下面就是Geoffrey Hinton,如果你不认识他的话:

然后系统会开始给这些关系起名字:
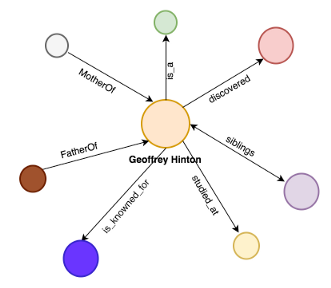
这个系统可以在一段时间内找到连接的连接,从而为我们的“搜索字符串”创建一个表示不同关系的巨大图。
为此,知识图谱使用了三元组。像下面这样的:
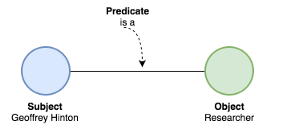
正如你所看到的我们有一个主语(Geoffrey Hinton)与宾语(Researcher),然后通过一个谓语(is a)联系起来。这对我们人类来说可能听起来很简单,但是它需要一个非常全面的框架,机器才能够进行处理。
这是知识图谱形成的方式,也是我们使用本体和语义链接数据的方式。
那么,我们需要什么来创建一个成功的知识图谱呢?来自Cambridge Semantics的Partha Sarathi为此写了一篇很棒的博客,你可以看一看:
https://blog.cambridgesemantics.com/creating-a-successful-enterprise-knowledge-graph
总而言之,他说我们需要: - 能够构想它的人:你需要具有业务关键主题专业知识和技术交叉的人员 - 数据多样性,尽可能还有大量的数据:采用企业知识图谱的价值和规模与所包含数据的多样性成正比 - 一个能够构建它的好产品:知识图谱需要具有良好的管理性、安全、易于连接到上下游系统、可进行大规模分析,而且往往是云友好的。因此,用于创建现代企业知识图谱的产品需要为自动化、支持各种输入系统的连接器、为下游系统提供标准的数据输出、快速分析任何规模的数据以及使管理变得友好进行优化。
可以阅读下面的文章进一步了解如何创建一个知识图谱:
https://info.cambridgesemantics.com/build-your-enterprise-knowledge-graph
第三节 知识图谱例子
Google:

Google基本上是一个巨大的知识(加上更多的补充)图谱,他们可能在此基础上创建了最大的Data Fabric。Google有数十亿的事实,包括关于数百万对象的信息和关系。并允许我们通过他们的系统去搜索,以发现其中的“洞察力”(insights)。
LinkedIn:

我最喜欢的社交网络LinkedIn有一个巨大的知识图谱,它建立在LinkedIn上的“实体”之上,比如成员、工作、头衔、技能、公司、地理位置、学校等等。这些实体和它们之间的关系构成了专业世界的本体。
而“洞察力”(insights)帮助领导者和销售人员做出商业决策,并提高LinkedIn的成员参与度:
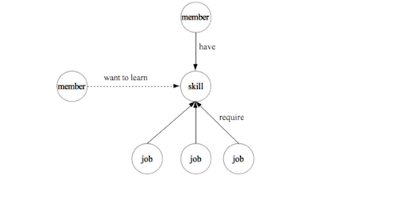
记住,LinkedIn(以及几乎所有)的知识图谱都需要随着新成员的注册、新职位的发布、新公司、技能和头衔出现在成员简介和职位描述中等等而进行扩展。
你可以阅读下面的文章了解更多关于LinkedIn中的知识图谱:
https://engineering.linkedin.com/blog/2016/10/building-the-linkedin-knowledge-graph
金融机构知识图谱:
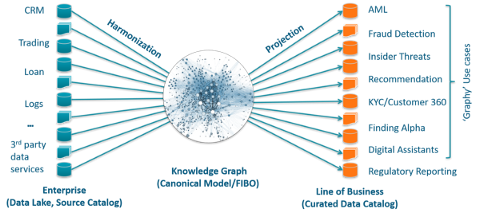
在下面Marty Loughlin的这篇文章中,他展示了Anzo平台可以为银行做些什么,在文章中你可以看到,这项技术不仅与搜索引擎相关,而且可以处理不同的数据。
https://blog.cambridgesemantics.com/why-knowledge-graph-for-financial-services-real-world-use-cases
在文章中,他展示了知识图谱如何帮助这类机构: - 用于分析和机器学习的另类数据(Alternative Data) - 利率互换风险分析 - 贸易监测 - 欺诈行为分析 - 特征工程与选择 - 数据迁移
总结

要创建知识图谱,你需要语义和本体来找到一种有用的方法来链接数据,这种方法惟一地标识数据并将数据与公共业务术语连接起来,从而构建Data Fabric的底层结构。
当我们构建一个知识图谱时,我们需要使用本体和语义形成三元组来链接数据。此外,知识图谱的构建基本上取决于三件事:构想它的人、数据多样性和构建它的好产品。
在我们周围有很多我们甚至不知道的知识图谱的例子。世界上大多数成功的公司都在实现和迁移它们的系统以构建Data Fabric。